Crowd Workers Are an Integral Piece of the Ethical AI Puzzle – Part 3
Building ethical AI isn’t a one-and-done checkbox-marking exercise – it’s a continual process made up of many nuanced considerations and decisions. It’s therefore not only our responsibility to build AI models that are robust to bias, but also to train and maintain them with unbiased, representative data to begin with. That’s why we must be mindful of our data collection practices and in particular, the role of crowd sourcing platforms in collecting that data.
In part three of our series on crowd work and its place in the ethical AI life cycle, we look at and challenge the popular status of crowd work as “low status” labor – a destructive distinction considering its importance to developing fair, equitable, and ethical AI – and what we can and have done to counter those perceptions. We also dive deeper on issues of communication both within and outside of crowd work platforms and what we can do to improve them.
The value and status of crowd work
Directly related to the pay discussion is the all-too-common notion that crowd work is low status or disposable, often because it has historically been a low paid, high-turnover type of piecework. Other reasons stem from worker skill-to-task mismatch, as crowd work is often popular amongst the under- or unemployed, a group that ranges from those without college education to those with advanced degrees. As a result of these associations, it is also viewed as work that has little opportunity for career advancement or professional development.
While that may be largely true of other platforms, Defined.ai has endeavored to change this, seeing the expertise in the workers that Neevo attracts, and the potential in further developing that expertise. One of Defined.ai’s ethical focuses thus revolves around skills cultivation and training for our crowd workers. Not only does Neevo actively attempt to attract skilled crowd workers for tasks, but it also offers training and professional development courses on the platform to improve crowd worker skills and encourage worker investment in the platform itself. This in turn also results in better data collection and annotation for the types of projects hosted on the platform, and encourages specially trained workers to return to the platform for further participation.
Part and parcel of this are the number of hands-on Neevo staff that oversee projects, directing and interacting with crowd workers to ensure that project requests are executed to data requesters’ specific needs. This may for instance include tasks for interactive voice response models or IVR, where crowd members are directed by Neevo staff to recreate specific customer service call scenarios, capturing as many variations of customer service audio as possible to comprehensively train a customer service AI.
Opening lines of communication between workers and requesters
Another issue of crowd work is its opacity from multiple angles.
First, there is the opacity between workers and the requester. Workers are only exposed to the task at hand – for example, a task requiring the worker to speak several lines of dialogue for audio recording. Workers are typically not given the context of their contributions beyond what can be gleaned from a straightforward set of instructions, meaning they are never given a reason as to why they should be doing what they are doing. To a machine, this may be enough, but is often too little for humans as a paucity of information makes them incapable of fully appreciating the purpose and the importance of the work, thus diminishing commitment to it.
This is further complicated by NDAs put in place by requesters around projects which limit how much disclosure can be given to workers. However, as in the above example, this often doesn’t preclude the option of giving limited context, such as “this work will help train an assistive services AI for those who are vision impaired.” Unlike machines, human beings often need to ascribe meaning to their actions and they value trust – trusting people enough to give them contextual information, even if limited in scope, helps the worker and the requester clarify the stakes of the work and why dedication to it is important.
Reversing angles, there’s the opacity of the worker from a requester’s standpoint. Though there are now many commissioned data projects that require a certain type of worker – e.g., native speakers of a given language, workers with specific tech or medical experience, etc. – requesters rarely know anything about the people that collect the data they request. This can complicate model training and evaluation down the line, as data could be collected by a self-selecting and unrepresentative slice of the population.
It’s a little different on Neevo, however. As one of Defined.ai’s ethical AI missions is to collect diverse, representative data, we not only curate a diverse set of contributors for each task, we also provide requesters metadata that details the demographic distributions of the data and its contributors. This in turn gives them confidence that models trained on this data will be robust to bias, and if necessary, can focus on certain key demographics – e.g., a US Southwest-based customer service AI that needs robust data representation for a Spanish-speaking demographic to better understand the local consumer base speaking Mexican Spanish and Mexican Spanish-accented English.
Take a look below at a sample visualization of some of the metadata we provide with one of our datasets, broken down by age, gender, accent, and phonetic distribution – detailed information that can be integral for any data scientist developing an AI speech model
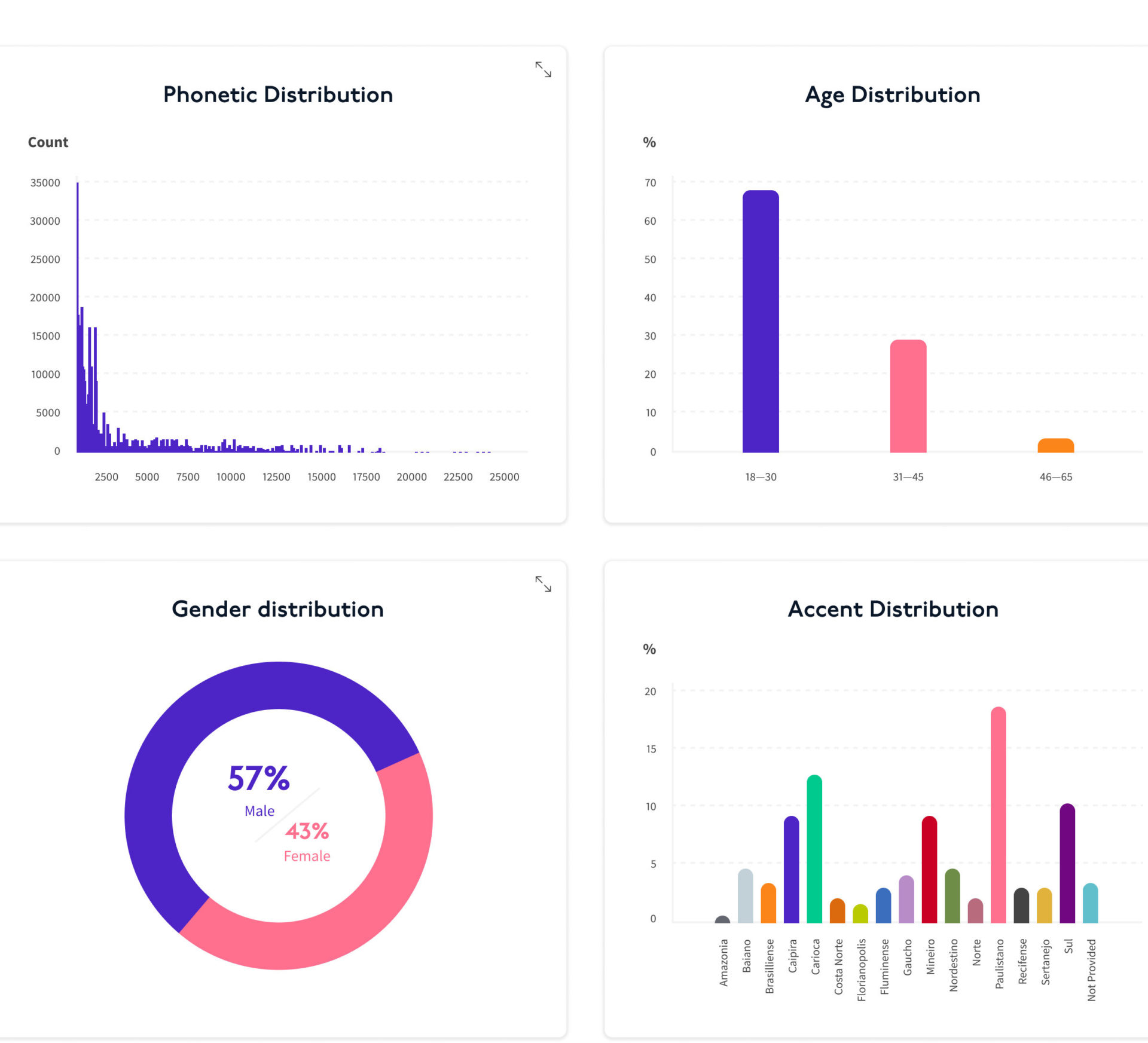
See more metadata breakdowns in datasets offered on the Defined.ai Marketplace
Lastly, there’s the opacity of crowd work to the general public. As mentioned previously, people are generally unaware that the AI-powered services they use are supported by thousands of crowd workers gathering, labeling, and refining data for those services. While most people have opinions on gig workers in ridesharing and delivery app-based services, crowd work’s absence from the gig work discussion has seen only the most popular and well-known types of platform work regulated.
This isn’t to say, however, that this will always be the case. With the growing awareness of how tech rules our modern lives, policymakers will inevitably scrutinize the role of crowd work in their attempts at refining AI legislation in the United States and the European Union. Whether crowd work will rise in popular understanding the way that Lyft and Uber drivers have remains to be seen, but crowd workers will, in time, become a recognized and protected class of workers. As such, it is perhaps wisest to get ahead of things now to improve crowd work not only for the sake of better data and better crowd working conditions, but to be in line with coming regulatory changes to minimize disruption.
The above are all arguments for opening and broadening lines of communication, promoting awareness of crowd work to all. From a platform perspective, Defined.ai has made inroads by the aforementioned metadata initiative, as well as in providing full-time staff to communicate directly with crowd workers needing context and clarification of tasks. While we’re also bound by the NDAs put in place by requesters, we understand the necessity of giving feedback and context – most people, if given the chance to understand the “what” and “why” of the importance of their contribution, will respond with their best effort.