
Accelerating Data-Driven Decisions at Defined.ai
Usually we need to make quick decisions and ideally we’d like to make them based on insights derived from data. However, this is not always possible. For example, we may not have a dashboard displaying the needed information. Also, it may take so long to elicit the requirements for a new dashboard, and implement and test the ETLs, that by the time the dashboard is ready, the question is no longer valid. When this happens, most organizations facing this common challenge give up and make the decision based on guesswork.
At DefinedCrowd, we believe this is not the way to go and that there is an alternative. We believe we can overcome the challenge by empowering all people in the organization to safely access the data we produce, allowing them to leverage the data to perform explorations and answer questions.
Adopting Apache Superset
In order to solve the aforementioned problem, we are currently experimenting with Apache Superset to empower everyone in our organization to make decisions based on data. Apache Superset is connected to our data lake and databases and additionally offers a SQL interface for querying them. The results of these queries can be plotted in a dashboard that can be safely shared with other people. With this tool, everyone with basic SQL knowledge can perform simple queries and answer questions without needing to delegate it to specialized teams.
Of course, this approach of making data access universal within the company poses several challenges. How do we ensure only authorized users can access sensitive data? How can we integrate these tools with our data infrastructure and our data sources?
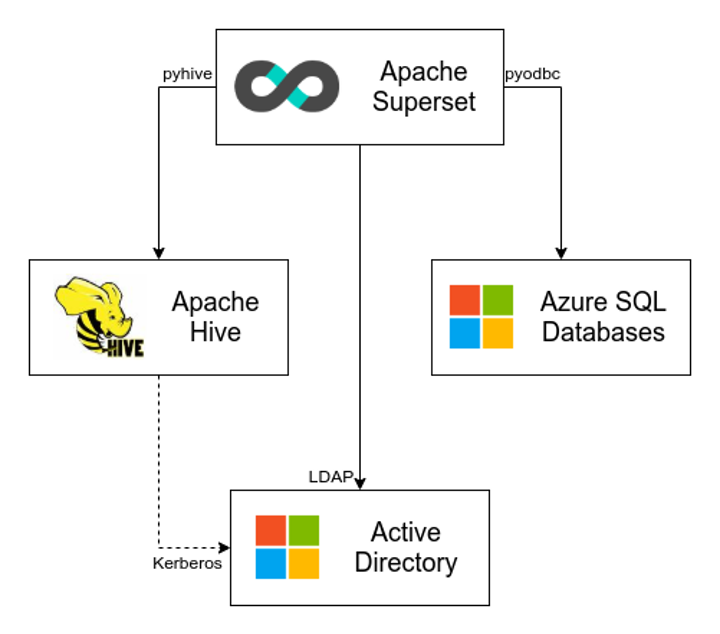
In a nutshell, as depicted in the image above, adding Apache Superset to our data infrastructure requires three different integrations:
- With our Active Directory, using the LDAP protocol. This ensures authenticated access to Apache Superset with the same credentials we use for our e-mail and other platforms.
- With the Apache Hive service running in our Azure HDInsight cluster, using the PyHive library. Since Apache Hive is the entry point to our data lake, users of Apache Superset will have the ability to query it.
- With replicas of our operational Azure SQL databases, using the pyodbc library. Occasionally we need to query our operational data directly, either because a certain set of data is not propagated to the data lake, or because it takes a bit longer than what we can wait.
Let’s look at the ways we are addressing these challenges.
Integration With Active Directory
Apache Superset relies on Flask AppBuilder Security to handle authentication and authorization. Since Flask AppBuilder supports LDAP authentication out of the box, we only have to configure it correctly to enable authentication for our Active Directory users.
Configuration of Apache Superset is done by setting the relevant values in a file named superset_config.py, to be included in the PYTHONPATH. To integrate it with the LDAP, the following configuration must be included in the superset_config.py file:
from flask_appbuilder.security.manager import AUTH_LDAP
AUTH_TYPE = AUTH_LDAP
AUTH_LDAP_SERVER = "ldap://"
AUTH_LDAP_BIND_USER = "superset.service@YourDomain.com"
AUTH_LDAP_BIND_PASSWORD = "<BIND_USER_PASSWORD>"
AUTH_LDAP_SEARCH = "dc=YourDomain,dc=com"
AUTH_LDAP_SEARCH_FILTER = "(memberof=CN=SupersetGroup,OU=Users,DC=YourDomain,DC=com)"
AUTH_LDAP_UID_FIELD = "sAMAccountName"
AUTH_USER_REGISTRATION = True
AUTH_USER_REGISTRATION_ROLE = "Gamma"With most of the configuration parameters above pretty much self-explanatory, you can double check their meaning in the Flask AppBuilder documentation. We’d like to point out that the AUTH_LDAP_SEARCH_FILTER is quite useful in controlling which users can access Apache Superset. In this example, only users of the group SupersetGroup will successfully authenticate, and you can define your own LDAP query to suit your needs.
We decided to use the sAMAccountName field as the username in Apache Superset, so that we could make use of the impersonation feature when integrating with Apache Hive (we’ll cover this in more detail in the next section). Finally, by enabling user self-registration, any user that belongs to the given group can automatically create an account in their first login and the Gamma role of Apache Superset is assigned by default.
Integration With Apache Hive
In our data infrastructure, Apache Hive is the main entry point to run queries in our data lake. We’re currently relying on the Azure HDInsight service to run our Apache Hadoop ecosystem and we have their Enterprise Security Package enabled to ensure that all access to data is authenticated and authorized. Under the hood, it connects with Azure Active Directory Domain Services and enables the Hadoop secure mode, so that all operations in the cluster require Kerberos authentication.
PyHive Support for Thrift Over HTTP
Access to Apache Hive in Apache Superset is supported using PyHive but using it in this context posed a challenge for us: PyHive didn’t support Thrift over HTTP. To allow remote clients to execute queries, Apache Hive implements a service named HiveServer2 that exposes a Thrift interface. By default, this interface runs over TCP but it can also be configured to run over HTTP. In the Azure HDInsight service, the default is to have the HiveServer2 Thrift interface running over HTTP and other dependencies of our data infrastructure only support HTTP.
With this challenge in front of us, we decided to roll up our sleeves and implement in PyHive the support for Thrift over HTTP. After some learning and debugging with the Thrift and PyHive libraries we were able to implement this support. We contributed to the open source community by submitting this implementation proposal. If you’re interested in using it, you can check its status in these pull requests:
Kerberos Authentication
Now that PyHive supports Thrift over HTTP, it’s technically possible to integrate Apache Superset in our architecture out of the box. The first step is to ensure that Apache Superset can authenticate itself as a Kerberos user in Apache Hive. For this, the following steps were taken:
- Installed Kerberos (the installation guide can be found here).
- Generate a keytab file. This file can be used to authenticate the user without entering the password again. The bash script below was used to generate the file automatically:
printf "%b" "addent -password -p username@YourDomain.com -k 1 -e RC4-HMAC \n$pass\nwrite_kt username.keytab" | ktutil- Having the keytab file, we were able to authenticate the user creating a Kerberos ticket. To do that, we just had to run the following bash script:
kinit username@YourDomain.com -k -t username.keytab- The last step was to guarantee that the Kerberos ticket did not expire while the user was still active. As we have a ticket lifetime of 24 hours, we opted to have a script running every 12 hours using crontab. Basically, this script runs the command shown in the previous step.
At this point, a Kerberos ticket was created, renewing while the user is active.
Apache Superset Configuration
Once the Kerberos authentication is in place, we can finally create the Database Source for Apache Hive in Apache Superset. The SQLAlchemy URI should look like:
hive://{HIVE_HOSTNAME}:10001/default?auth=KERBEROS&kerberos_service_name=hive&thrift_transport_protocol=httpIt’s important to point out that when using Thrift over HTTP the default port is 10001, while the default port for Thrift over TCP (i.e. binary transport mode) is 10000. If you find yourself having to use port 10000 it’s likely that your HiveServer2 service is configured for binary mode. If that’s the case, you simply must define thrift_transport_protocol=binary in the SQLAlchemy URI.
User Impersonation in Apache Hive
As mentioned before, one important aspect of our data infrastructure is that all data operations in our data lake are correctly authenticated and that would not be possible without activating impersonation in this Apache Hive data source. In short, even though Apache Superset uses the service account authenticated via Kerberos to establish sessions with Apache Hive, all operations executed in those sessions are associated with the user logged in to Apache Superset.
For this to be possible, the service account user must be configured as a proxy user in the Hadoop configuration. The following values should be added to the Hadoop core-site configuration:
hadoop.proxyuser.data_bind.groups=*
hadoop.proxyuser.data_bind.hosts=*Finally, even though Apache Superset indicates that hive.server2.enable.doAs should be enabled, when integrating with an Apache Hive service running in Azure HDInsight with ESP enabled you should not enable this property. This is specific to the way the ESP is implemented in Azure HDInsight, so if you’re using a different Hadoop ecosystem you probably need to enable that property.
Integration With Azure SQL
The operational data of our platform is being stored in Azure SQL databases and it needs to be accessed occasionally by our users. As mentioned, this access is needed either because some data is not being propagated to the data lake yet or because it needs to be analyzed right away.
Superset makes use of SQLAlchemy, which provides a set of adapters that we can use to establish a connection with a SQL Server database. The adapter we chose was pyodbc and it can be installed by following the steps below:
- Install pyodbc following the Microsoft instructions;
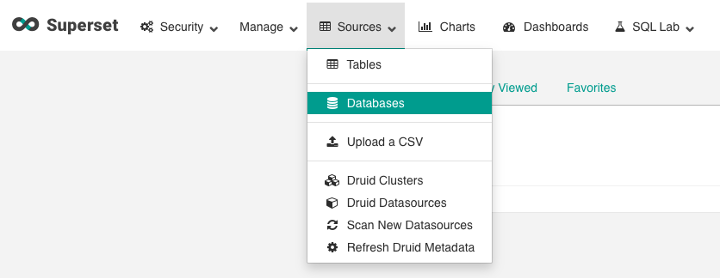
- Setup the connection using Superset UI:
- Click on Sources and then Databases:
- Add a new record:

- Add a new database filling in the database name and the SQLAlchemy URI:
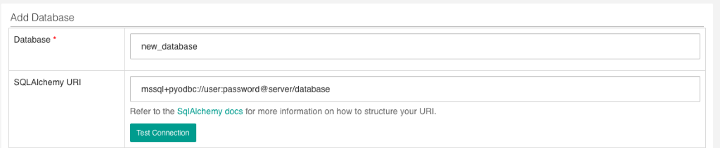
For the connection above, we created a data-masking user, which means that all queries are made on behalf of this user. On top of this user, a data mask was applied to hide the data classified as sensitive; for example, personal and commercial data. This way, we maintain safe access to the data.
Next Steps
Overall, we are very excited with the technical solution we found in order to integrate all these components of our architecture. For Superset to become a long-term unified data interface in our company, we’re planning to enrich its functionality by:
- Adding more data sources (Intercom, Salesforce, etc.),
- Enabling queries and visualizations across multiple data sources and
- Creating optimized databases and auxiliary data structures for common queries so that query times are reduced.